Accès aux données¶
Les données de niveau d’échantillonnage complet pour chaque organisme peuvent être téléchargées depuis le tableau de bord AMRnet lui-même, en utilisant le bouton « Télécharger la base de données (CSV) en bas de la page. De plus, vous pouvez accéder aux données AMRnet via l’API décrite ci-dessous.
Architectures : Les architectures de l’API ont 2 options développées pour le projet qui incluent :
1. Télécharger les données via un seau¶
Note
Nom de l’organisme pour télécharger des fichiers depuis AWS : Escherichia coli (diarrheagenic) en tant que amrnetdb-Escherichia_coli_ diarrheagenic; Escherichia coli en tant que amrnetdb-Escherichia_coli; Klebsiella pneumoniae en tant que amrnetdb-Klebsiella_pneumoniae; Neisseria gonorrhoeae en tant que amrnetdb-Neisseria_gonorrhoeae; Salmonella (invasive non-typhoidal) en tant que amrnetdb-Salmonella_enterica_invasive_nontyphoidal; Salmonella (non-typhoidal) en tant que amrnetdb-Salmonella_enterica_nontyphoidal; Shigella en tant que amrnetdb-Shigella_EIEC; Salmonella Typhi en amrnetdb-Salmonella_Typhi
a. Données accédant à l’aide du navigateur¶
i. Visualisation des fichiers disponibles¶
Étape 1 : Ouvrez un navigateur web (Chrome, Firefox, Safari, etc.).
Étape 2: Naviguez vers l’URL du bucket racine en cliquant sur https://amrnet.<unk> <unk> s.com/.
Étape 3: Cette URL mène à une représentation de texte XML listant tous les fichiers disponibles dans le compartiment Amazon S3. Le format XML affichera des informations sur chaque fichier, comme sa clé (nom), sa date de dernière modification, sa taille, etc.
ii. Recherche d’un organisme spécifique¶
Étape 1 : Utilisez la fonction de recherche de votre navigateur (Ctrl-F sous Windows/Linux ou Cmd-F sur Mac).
Étape 2 : Tapez le nom du fichier en fonction de l’organisme que vous recherchez dans la zone de recherche. Ceci mettra en évidence toutes les occurrences du nom de l’organisme dans le texte XML, ce qui facilitera la localisation du fichier spécifique associé à cet organisme.
iii. Téléchargement d’un fichier¶
Étape 1 : Une fois que vous avez trouvé le champ
<Key>qui contient le nom du fichier qui vous intéresse, notez le nom du fichier.Étape 2 : Ouvrez un nouvel onglet dans votre navigateur.
Étape 3: Copiez l’URL du bucket racine
https://amrnet.<unk> <unk> s.comdans la barre d’adresse du nouvel onglet.Étape 4 : Ajoute un slash
/à la fin de l’URL, suivi du contenu du champ<Key>(nom du fichier).Étape 5 : Appuyez sur Entrée et votre navigateur devrait démarrer automatiquement le téléchargement du fichier. Cette méthode a été testée pour fonctionner dans Chrome, Firefox et Safari.
OU
Copiez l’URL ci-dessous et modifiez le nom de l’organisme ajouté à la fin amrnet-
amrnetdb-Escherichia_coli_ diarrheagenic.csv.gz basé sur la liste d’organismes donnée ci-dessus.
Exemple:
https://amrnet.s3.amazonaws.com/amrnet-latest/amrnetdb-Escherichia_coli_ diarrheagenic.csv.gz
b. Données accédant à l’aide de la ligne de commande¶
Étape 1 : Ouvrez votre terminal.
Étape 2 : Utilisez la commande suivante pour télécharger les données à partir de l’URL fournie :
curl -O https://amrnet.s3.amazonaws.com/
De même, si vous devez télécharger un fichier spécifique à partir de l’URL, vous devez spécifier le nom du fichier dans l’URL. Par exemple :
curl -O https://amrnet.s3.amazonaws.com/filename
Exemple:
curl -O https://amrnet.s3.amazonaws.com/amrnet-latest/amrnetdb-Escherichia_coli_ diarrheagenic.csv.gz
c. Accès aux données à l’aide de l’outil S3cmd¶
L’outil s3cmd est un utilitaire en ligne de commande polyvalent et puissant conçu pour interagir avec Amazon S3 (Simple Storage Service). Il simplifie les tâches telles que la navigation, le téléchargement et la synchronisation des fichiers à partir des compartiments S3. Cet outil est particulièrement utile pour gérer les grands ensembles de données et automatiser les flux de travail impliquant le stockage S3.
2. Télécharger les données via l’API¶
Envoyez un email à amrnetdashboard@gmail.com pour demander un jeton d’API.
Exemple:
Subject: Request for API Token
I am writing to request an API token for accessing the AMRnet database. Below are the specific details for my request:
Organism Name: Escherichia coli
Vous recevrez un e-mail de notre part avec tous les détails nécessaires. Comme : API_TOKEN_KEY, collection, base de données, dataSource.
Une fois que vous recevez ces détails, utilisez la méthode ci-dessous pour télécharger les données requises.
Pour télécharger des données avec un pays et une date spécifiques, ajoutez un filtre.
Exemple de code pour télécharger toutes les données pour un organisme:
curl --location --request POST 'https://eu-west-2.aws.data.mongodb-api.com/app/data-vnnyv/endpoint/data/v1/action/find' \
--header 'Content-Type: application/json' \
--header 'Access-Control-Request-Headers: *' \
--header 'api-key: <API_TOKEN_KEY>' \
--data-raw '{
"collection":"<COLLECTION_NAME>",
"database":"<DATABASE_NAME>",
"dataSource":"<dataSource_NAME>"
}'
Exemple de code pour télécharger les données avec les filtres Date et Pays pour un organisme :
curl --location --request POST 'https://eu-west-2.aws.data.mongodb-api.com/app/data-vnnyv/endpoint/data/v1/action/find' \
--header 'Content-Type: application/json' \
--header 'Access-Control-Request-Headers: *' \
--header 'api-key: <API_TOKEN_KEY>' \
--data-raw '{
"collection":"<COLLECTION_NAME>",
"database":"<DATABASE_NAME>",
"dataSource":"<dataSource_NAME>",
"filter": {"$and": [{"Date": 2015},{"Country": "United Kingdom"}]}
}'
Exemple de code pour télécharger les données avec un seul filtre, par exemple Date pour un organisme:
curl --location --request POST 'https://eu-west-2.aws.data.mongodb-api.com/app/data-vnnyv/endpoint/data/v1/action/find' \
--header 'Content-Type: application/json' \
--header 'Access-Control-Request-Headers: *' \
--header 'api-key: <API_TOKEN_KEY>' \
--data-raw '{
"collection":"<COLLECTION_NAME>",
"database":"<DATABASE_NAME>",
"dataSource":"<dataSource_NAME>",
"filter": {"Date": 2015}
}'
Exemple de code pour télécharger les données et les enregistrer en JSON :
curl --location --request POST 'https://eu-west-2.aws.data.mongodb-api.com/app/data-vnnyv/endpoint/data/v1/action/find' \
--header 'Content-Type: application/json' \
--header 'Access-Control-Request-Headers: *' \
--header 'api-key: <API_TOKEN_KEY>' \
--data-raw '{
"collection":"<COLLECTION_NAME>",
"database":"<DATABASE_NAME>",
"dataSource":"<dataSource_NAME>",
"filter": {"Date": 2015}
}' > output.json
Note
Pour tester vos requêtes cURL, vous pouvez utiliser l’outil en ligne Run Curl Commands Online. Cet outil fournit un moyen pratique d’exécuter et de tester vos commandes cURL directement dans votre navigateur Web sans avoir à installer de logiciel supplémentaire.
a. Ligne de commande¶
Pour télécharger des données en utilisant notre API, veuillez suivre les étapes suivantes :
Une fois que vous avez un jeton d’API, remplacez
<API_TOKEN_KEY>dans la commande suivante par le jeton d’API que vous avez reçu.Déterminez la base de données spécifique et la collection dont vous avez besoin de données.
Ouvrez votre interface en ligne de commande (CLI) ou votre terminal et exécutez la commande curl suivante pour télécharger des données.
Si vous voulez enregistrer les données de réponse dans un fichier, vous pouvez utiliser l’option -o avec curl. Cette commande va enregistrer les données de réponse dans un fichier nommé data.json dans le répertoire courant.
b. Plateforme¶
Note
Les utilisateurs ont la flexibilité d’accéder à l’API par le biais de leur plate-forme préférée. À titre d’illustration, nous fournissons des conseils sur l’utilisation de l’outil Postman pour accéder aux données via l’API.
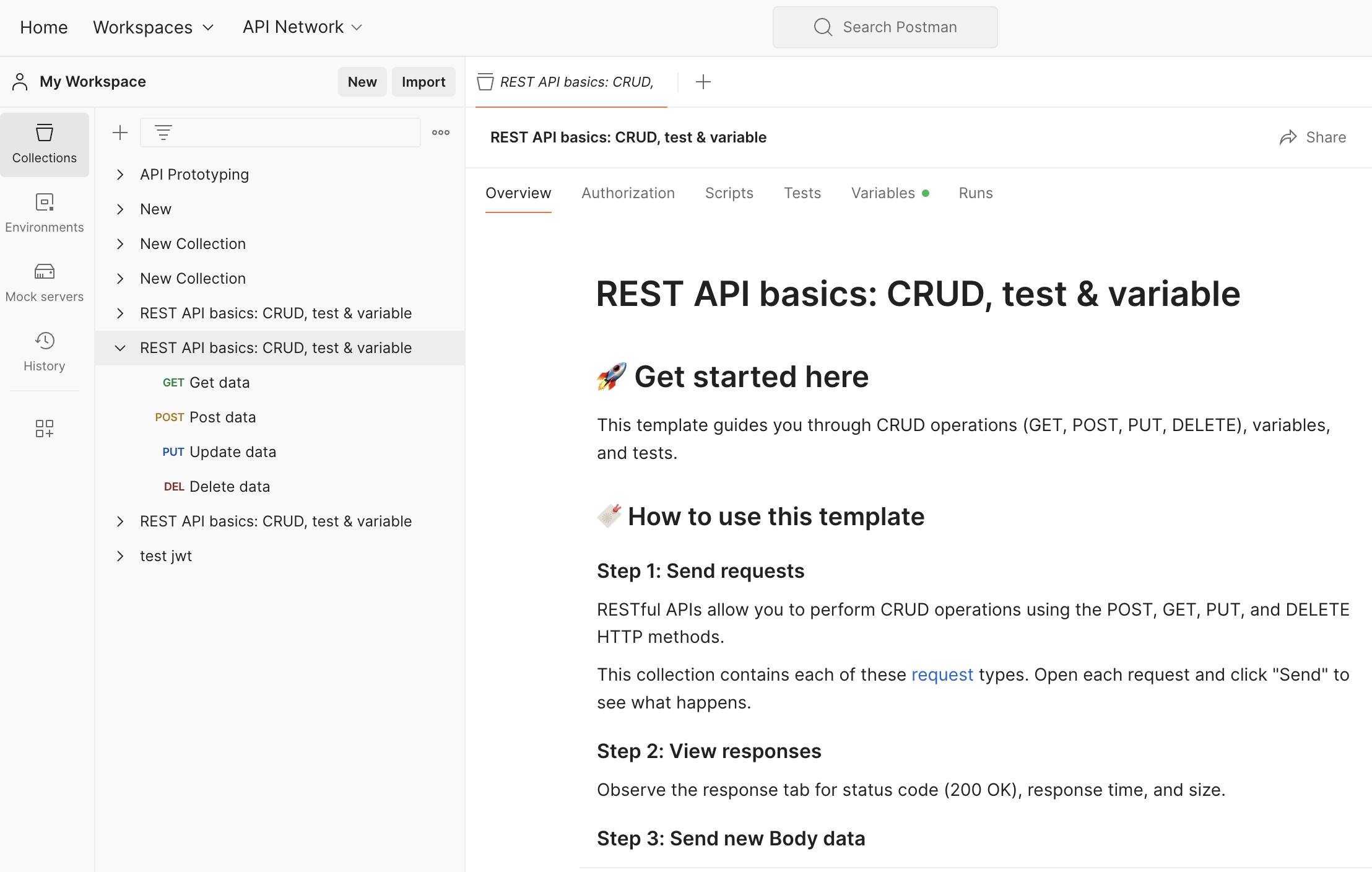
Étapes pour importer l’exemple de commande cURL en utilisant Postman
Ouvrez Postman.
Connectez-vous avec vos identifiants et « découvrez ce qu’un postman peut faire »
Cliquez sur le bouton « Importer ».
Coller la commande cURL dans Importation :
Revoyez les détails de la requête importée et ajoutez
<API_TOKEN_KEY>dansHeadersdans Postman.
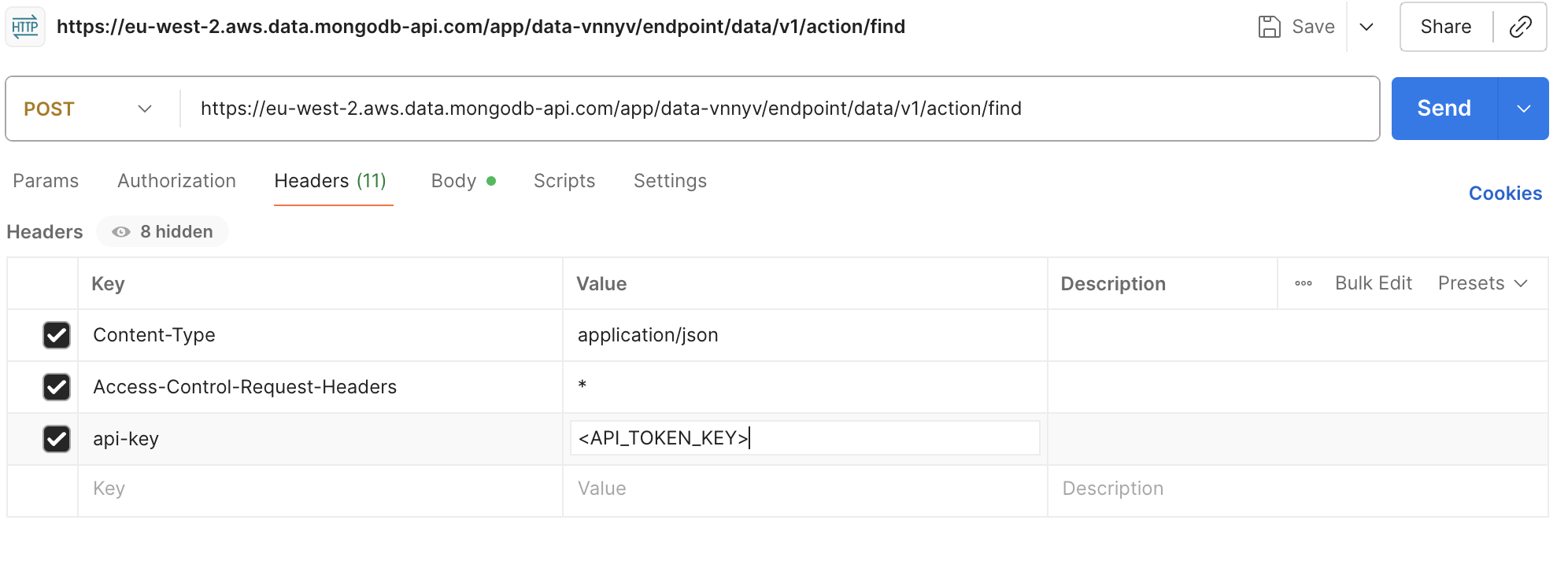
Remplacer le nom de la base de données et le nom de la collection en fonction des données à télécharger
Ajouter des filtres pour obtenir des données spécifiques dans
filter
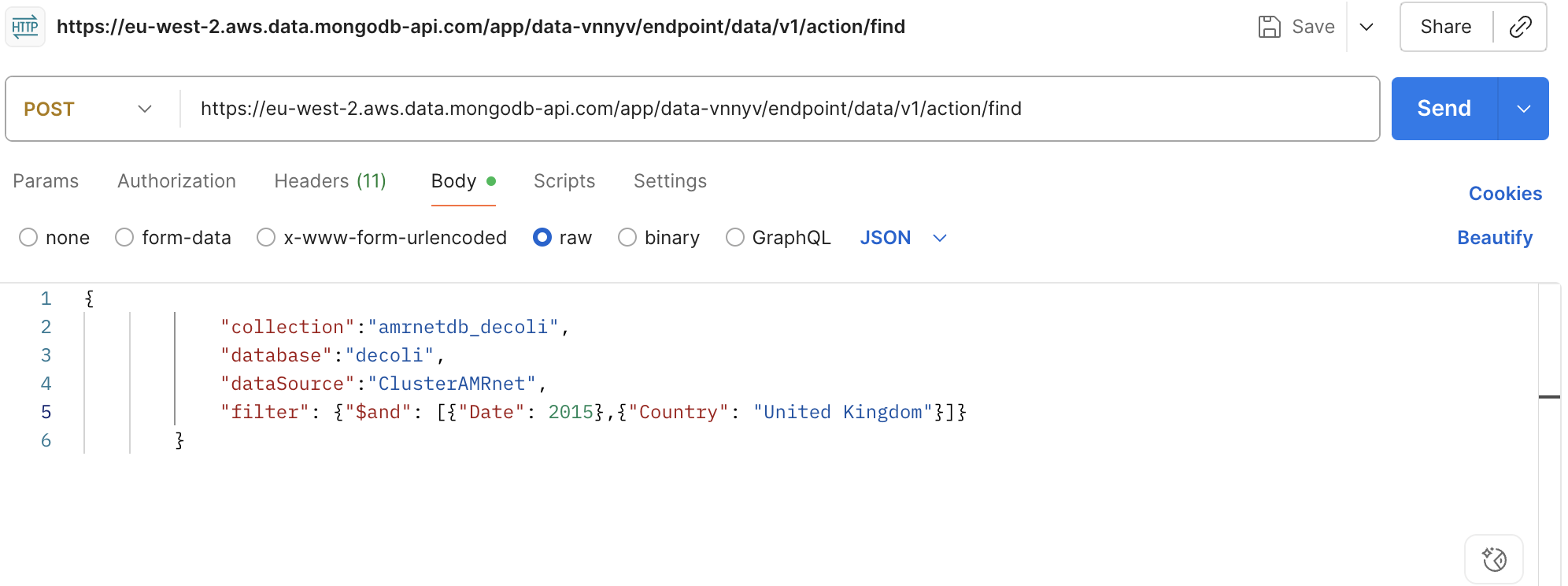
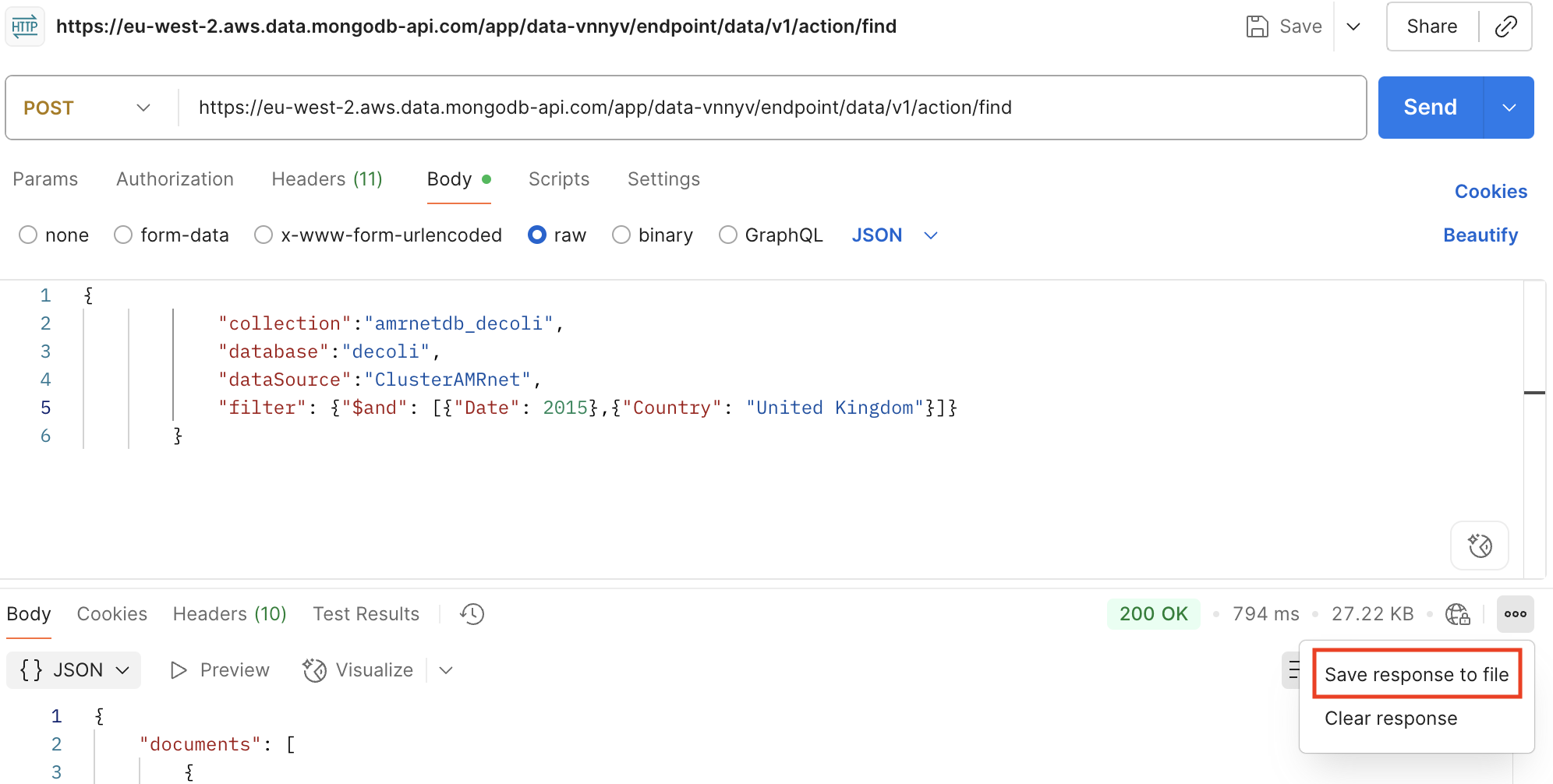
Cliquez sur « Envoyer » pour exécuter la requête et afficher la réponse.
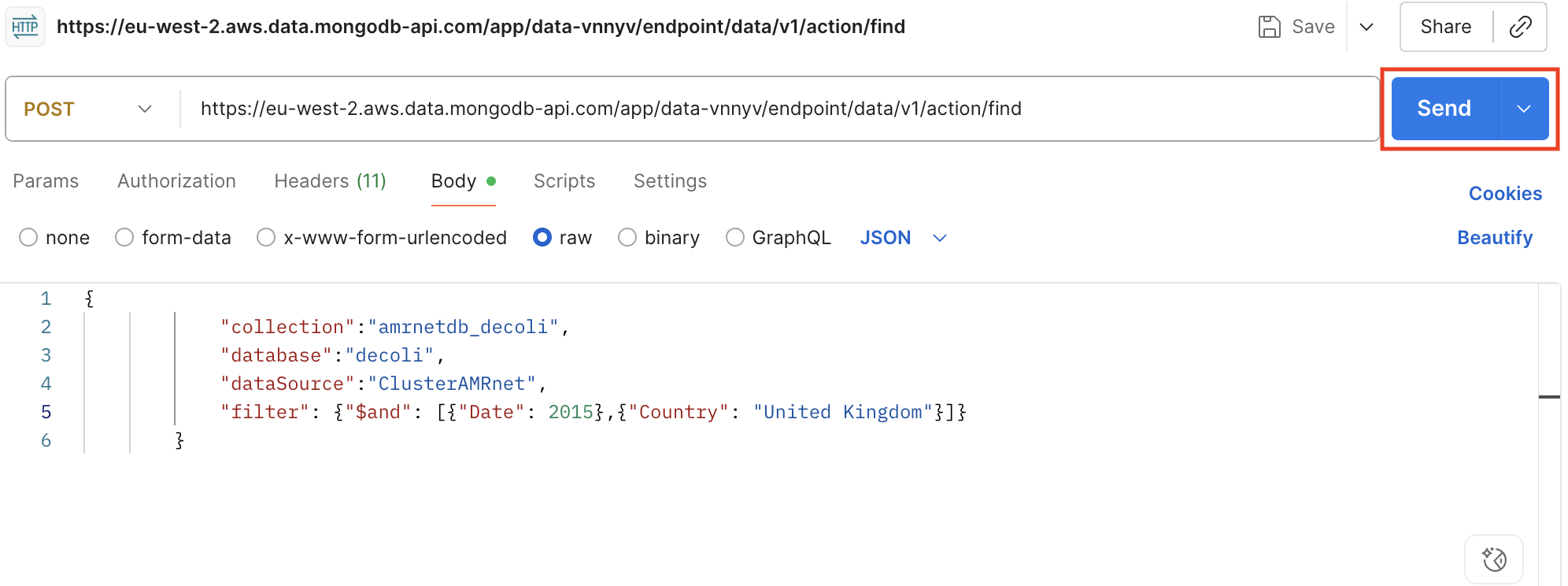
Enregistrer la réponse dans le fichier